
[ElasticSearch] Part 1 - 설치 + 기본 사용방법 02
[2] ES 실습하기
(1) Docker 설치하기(MacOS 기준)
1) 터미널에서 Docker 설치하기 (Homebrew 사용)
-
먼저 Homebrew가 설치돼 있는지 확인
brew --version -
Docker 설치(Docker Desktop 설치 - GUI포함)
brew install --cask docker -
설치 후 실행(회원가입 및 로그인 진행)

docker --version
2) docker-compose.yml 파일 만들기
-
실습용 폴더 만들기
mkdir elasticsearch-nori-test cd elasticsearch-nori-test -
docker-compose.yml 파일 생성 및 열기
touch docker-compose.yml open -e docker-compose.yml -
파일에 해당 내용 붙여넣기
version: '3' services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:8.11.1 container_name: elasticsearch environment: - discovery.type=single-node - xpack.security.enabled=false - ES_JAVA_OPTS=-Xms512m -Xmx512m ports: - "9200:9200" kibana: image: docker.elastic.co/kibana/kibana:8.11.1 container_name: kibana ports: - "5601:5601" environment: - ELASTICSEARCH_HOSTS=http://elasticsearch:9200 depends_on: - elasticsearch- [깨알 팁] docker-compose.yml
- 여러 컨테이너(서비스)를 한 번에 실행/관리 하기 위한 설정이다.
- 어떤 이미지를 가지고 컨테이너를 어떻게 실행할지 정의 (포트, 네트워크, 의존성 등 …)
- docker-compose.yml 구성 설명
version: '3’→ docker-compose 파일의 버전. 일반적으로 3버전이면 충분하다.image: [docker.elastic.co/elasticsearch/elasticsearch:8.11.1](http://docker.elastic.co/elasticsearch/elasticsearch:8.11.1)→ 사용할 Docker 이미지: Elasticsearch 8.11.1 버전container_name: elasticsearch→ 컨테이너의 이름을 elasticsearch로 지정environment→ 환경 변수 설정discovery.type=single-node→ 클러스터가 아니라 단일 노드 모드로 실행- [깨알 팁] 클러스터 vs 단일 노드 모드
-
용어 정리
용어 의미 노드(Node) Elasticsearch가 설치되고 실행되는 단일 서버 인스턴스. 하나의 Elasticsearch 실행 프로세스를 의미해. 클러스터(Cluster) 여러 개의 노드들이 연결되어 구성된 전체 시스템 그룹. 데이터를 분산해서 저장하고 처리함. 샤드(Shard) 인덱스를 물리적으로 나눈 조각. 클러스터 내 여러 노드에 분산 저장됨. 레플리카(Replica) 샤드의 복사본. 고가용성과 부하 분산을 위해 사용함. -
쉽게 이해하기 쉬운 비유
-
단일노드 vs 클러스터
비교 항목 단일 노드(single-node) 클러스터(cluster) 노드 수 1개 2개 이상 구성 목적 로컬 개발, 테스트 실서비스(확장성/고가용성) 데이터 저장 방식 한 노드에 전부 저장 샤드 단위로 분산 저장 장애 대응 불가능 (죽으면 끝) 가능 (다른 노드가 백업함) 예시 docker-compose로 개발환경 1개 띄울 때 AWS, GCP 등에서 노드 여러 개로 운영
ES는 원래 분산 시스템이다. 기본적으로 여러 대의 서버(노드)가 모여서 클러스터를 이루고, 데이터를 분산 저장, 분산 처리를 한다. 이는 ES의 강점 중 하나이다. 예를 들어, 서버가 3대가 있으면, 각각 데이터 일부를 저장, 동시에 처리가 가능하다. (속도+안정성 ↑)
- 로컬 개발이나 테스트를 할 경우 대부분 1대 노드만 써서 테스트를 한다. 그래서 굳이 클러스터 기능을 활성화할 필요가 없다. 단일 노드로 안 띄우면 ES가 다른 노드를 찾으려 하면서 부팅이 느려지거나 에러가 난다.
-
xpack.security.enabled=false→ 인증/보안 기능 끔 (개발 테스트용으로 편함)ES_JAVA_OPTS→ JVM 메모리 설정 (필요 시 조정 가능)
"9200:9200”→ ES 포트 연결 (로컬 PC의 9200 포트 → 컨테이너의 9200 포트 (REST API 호출용)image: [docker.elastic.co/kibana/kibana:8.11.1](http://docker.elastic.co/kibana/kibana:8.11.1)→ Kibana의 Docker 이미지 (Elasticsearch UI 툴)container_name: kibana→ Kibana 컨테이너 이름"5601:5601”→ 브라우저로 열 수 있도록 Kibana 웹 UI 포트 연결ELASTICSEARCH_HOSTS=http://elasticsearch:9200→ Kibana가 어디에 있는 ES랑 연결할지 설정depends_on: - elasticsearch→ ES가 먼저 실행된 다음 Kibana가 실행되게끔 설정
- 요약하자면, 이 compose 파일 하나로:
- localhost:9200 → ES REST API
- localhost:5601 → Kibana UI 접속
- [깨알 팁] docker-compose.yml
3) Docker Compose로 실행하기
-
compose 파일이 있는 폴더에서 아래 명령어 입력
docker-compose up -d-
옵션 -d는 백그라운드(숨김 모드)로 실행하겠다는 뜻

-
실행 확인하는 방법
docker ps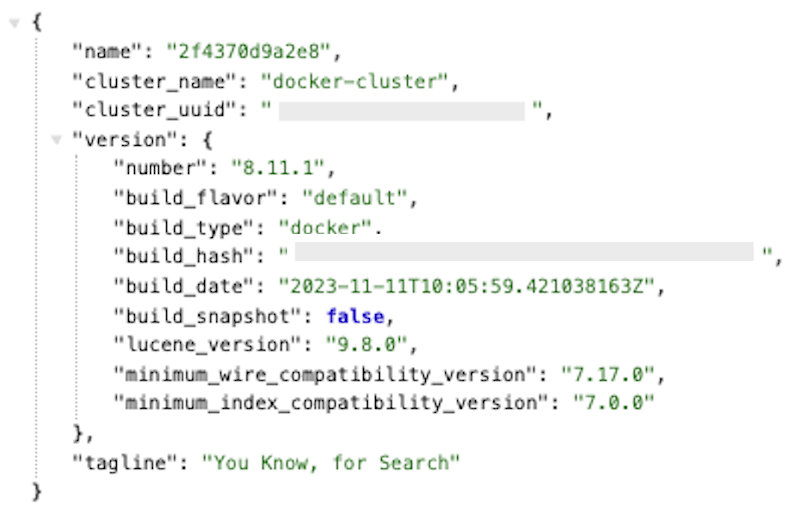
elasticsearch 와 kibana 두 컨테이너가 실행 중이어야하고, 둘 다 STATUS가 Up 상태면 성공
-
4) 브라우저에서 확인
- 이제 아래 주소로 접속
- ES 상태 확인 👉 http://localhost:9200
-
JSON 비슷한 응답 나오면 성공
- Kibana 웹 UI 👉 http://localhost:5601
-
처음엔 로딩 오래 걸릴 수 있음 (최대 30초~1분 정도)
-
5) Nori 플러그인 포함된 Docker 이미지 설치
-
폴더와 파일 만들기
elasticsearch-nori-test/ ├── docker-compose.yml └── elasticsearch-nori/ └── Dockerfilemkdir elasticsearch-nori touch elasticsearch-nori/Dockerfile open -e elasticsearch-nori/Dockerfile -
아래 내용을 Dockerfile에 붙여 넣고 저장, 닫기
FROM docker.elastic.co/elasticsearch/elasticsearch:8.11.1 RUN elasticsearch-plugin install analysis-nori --batchFROM [docker.elastic.co/elasticsearch/elasticsearch:8.11.1](http://docker.elastic.co/elasticsearch/elasticsearch:8.11.1)- 이 줄은 Elasticsearch 공식 이미지(8.11.1 버전)를 기반으로 시작하겠다는 의미이다.
FROM→ 기반으로 삼을 이미지 지정
RUN elasticsearch-plugin install analysis-nori --batchRUN→ Docker 이미지 생성 과정 중에 실행되는 명령이다.- 여기서는 Nori 분석기 플러그인을 설치하는 명령이다.
analysis-nori→ 한국어 형태소 분석기--batch→ “yes/no”를 물어보는 단계 없이 자동으로 설치하도록 하는 옵션
-
[깨알 팁] Dockerfile
Dockerfile은 커스텀 Docker 이미지를 만들기 위한 설정 파일이다. “이미지 안에 어떤 것을 넣을 것인지, 어떤 명령을 실행할 것인지“ 이런 내용을 넣는다. 이 파일을 바탕으로 docker build 명령을 실행하면 이미지를 생성할 수 있다.
-
[깨알 팁] Dockerfile vs docker-compose.yml
구분 Dockerfile docker-compose.yml 목적 커스텀 이미지를 만들기 위한 레시피 여러 컨테이너(서비스)를 한 번에 실행/관리하기 위한 설정 역할 하나의 Docker 이미지를 어떻게 만들지 정의 (OS, 파일, 플러그인 설치 등) 어떤 이미지를 가지고 컨테이너를 어떻게 실행할지 정의 (포트, 네트워크, 의존성 등) 구성 명령어 중심 (FROM, RUN, COPY 등) 서비스 중심 (elasticsearch, kibana 등) 사용 위치 docker build 명령어와 함께 사용 docker-compose up 명령어로 사용
6) docker-compose.yml 수정 (커스텀 이미지 사용)
-
기존 ES 설정을 아래처럼 바꾸기
version: '3' services: elasticsearch: build: context: ./elasticsearch-nori container_name: elasticsearch environment: - discovery.type=single-node - xpack.security.enabled=false - ES_JAVA_OPTS=-Xms512m -Xmx512m ports: - "9200:9200" kibana: image: docker.elastic.co/kibana/kibana:8.11.1 container_name: kibana ports: - "5601:5601" environment: - ELASTICSEARCH_HOSTS=http://elasticsearch:9200 depends_on: - elasticsearch
7) 기존 컨테이너 정리 및 커스텀 이미지 빌드 + 컨테이너 실행
-
정리
docker-compose down -
빌드 및 실행
docker-compose up --build -d- –build: 우리가 만든 Dockerfile로 이미지 빌드
- -d: 백그라운드 실행
-
실행 상태 확인
docker ps- ES랑 kibana가 Up 상태면 성공
(2) 인덱스 생성 및 데이터 조회하기
1) Nori 분석기 적용 인덱스 만들기
-
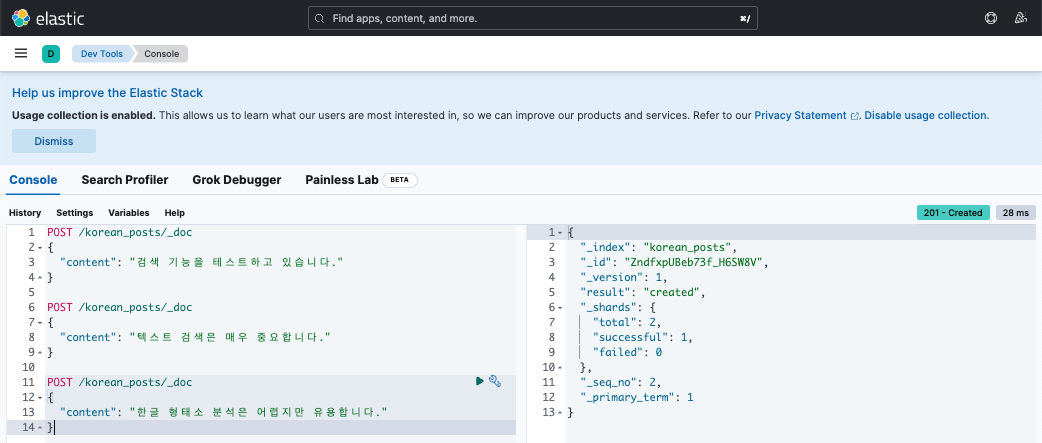
사용할 도구
Postman이나 curl 중 편한 거 써도 되고, Kibana UI에서 하고 싶으면 http://localhost:5601 → 왼쪽 메뉴 → “Dev Tools” → 콘솔에서 아래 쿼리 입력하면 된다.
-
인덱스 생성 쿼리 (korean_posts라는 이름)
PUT /korean_posts { "settings": { "analysis": { "analyzer": { "korean": { "type": "custom", "tokenizer": "nori_tokenizer" } } } }, "mappings": { "properties": { "content": { "type": "text", "analyzer": "korean" } } } }- “이 인덱스는 Nori로 형태소 분석해서 content 필드를 처리할 거야” 라는 뜻
-
실행 방법 예시 (curl)
curl -X PUT "localhost:9200/korean_posts" -H "Content-Type: application/json" -d '{ "settings": { "analysis": { "analyzer": { "korean": { "type": "custom", "tokenizer": "nori_tokenizer" } } } }, "mappings": { "properties": { "content": { "type": "text", "analyzer": "korean" } } } }'
-
실행 완료 시 나오는 값
{ "acknowledged": true, "shards_acknowledged": true, "index": "korean_posts" }
2) 인덱스 생성 쿼리 분석
PUT /korean_posts
{
"settings": {
"analysis": {
"analyzer": {
"korean": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "korean"
}
}
}
}
- 인덱스 생성 쿼리 분석
PUT /korean_posts: 이름이 korean_posts인 인덱스를 새로 생성-
"setting": 분석기(analyzer), 토크나이저(tokenizer) 등 텍스트 처리를 위한 설정"settings": { "analysis": { -> 텍스트 분석 관련 설정 (Analyzer, Tokenizer, Filter 등 "analyzer": { -> 분석기 "korean": { -> korean 이라는 이름의 사용자 정의(custom) 분석기 생성 "type": "custom", -> 기본이 아닌 '사용자 정의' 분석기임을 명시 "tokenizer": "nori_tokenizer" -> Nori 형태소 분석기 사용 } } } },nori_tokenizer: 한국어 문장에서 조사, 어미 등을 분리(형태소 단위)하고, 어간 중심으로 토큰화해주는 ES 기본 제공 형태소 분석기이다.
-
"mappings": 필드별 타입, 분석기 적용 방법 정의"mappings": { "properties": { -> 각 필드(컬럼)의 구조와 타입을 정의 "content": { -> 문서의 텍스트 필드 (예: 게시글 내용 등) "type": "text", -> 검색 가능한 텍스트 필드로 설정 "analyzer": "korean" -> 앞에서 정의한 사용자 정의 분석기 적용 } } }-
properties 예시
id title content 1 자율주행차 소개 자율주행차는 인공지능을 기반으로 한다 "properties": { "id": { "type": "long" }, "title": { "type": "text", "analyzer": "korean" }, "content": { "type": "text", "analyzer": "korean" } } -
properties 속성 종류
| 속성 | 설명 | 예시 | | — | — | — | | type | 필드 데이터의 타입 지정 (필수) | “type”: “text” | | analyzer | 텍스트 분석기 설정 (주로 text 타입일 때 사용) | “analyzer”: “nori” | | format | 날짜 포맷 지정 (date 타입에서 사용) | “format”: “yyyy-MM-dd HH:mm:ss” | | fields | 동일한 필드를 여러 방식으로 검색할 수 있게 설정 | “fields”: { “keyword”: { “type”: “keyword” } } |
-
기본적인 필드 예시
"title": { "type": "text", "analyzer": "nori" } -
날짜 필드에 format 추가
"created_at": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" } -
text + keyword 필드 동시 사용 (fields 활용)
"title": { "type": "text", "analyzer": "nori", "fields": { "keyword": { //이건 단순히 명명이다. 아무렇게나 변경 가능 "type": "keyword" } } }- fields는 하나의 필드를 여러 방식으로 다루고 싶을 때 사용
-
text 타입 : 전체 텍스트 검색(=분석기 적용) → title → match, match_phrase
{ "match": { //전체 텍스트 검색 "title": "자율주행차 기술" } } -
keyword 타입 : 정확한 일치, 필터링, 집계, 정렬 → title.keyword → terms, sort, filter
{ "aggs": { //그룹핑해서 집계 "top_titles": { "terms": { "field": "title.keyword" } } } }
-
-
데이터가 아래와 같이 저장되어있을 경우
{ "title": "자율주행차 기술의 발전" }-
ES 내부에서는 다음과 같이 저장이 된다.
필드명 저장 내용 예시 설명 title [“자율”, “주행차”, “기술”, “발전”] nori 분석기로 쪼개진 토큰들 (검색용) title.keyword “자율주행차 기술의 발전” (전체 문자열 그대로) 분석하지 않고 원문 그대로 저장 (정렬/집계용) 즉 하나의 필드를 두 버전으로 저장해두고, 사용시 목적에 따라 title 또는 title.keyword 를 선택하는 것이다.
-
-
fields 이름은 변경 가능하다. 다만, 공백없이/알파벳/숫자/언더스코어 만 사용가능하다.
"title": { "type": "text", "analyzer": "nori", "fields": { "hello": { "type": "keyword" }, // -> title.hello "hola": { "type": "keyword" }, // -> title.hola } }
→ 이렇게 하면 title은 전체 텍스트 검색용이고, title.keyword는 정렬·필터·집계용으로 사용 가능!
- fields는 하나의 필드를 여러 방식으로 다루고 싶을 때 사용
-
-
properties type 종류
타입 설명 text 텍스트 검색용 필드 (분석기 사용됨) keyword 정렬, 필터링, 집계용 (분석기 사용 안 함) integer 숫자 date 날짜/시간 boolean true/false object JSON 객체 (중첩 구조 가능) -
properties는 이 인덱스에 어떤 필드들이 들어올 거고, 어떻게 저장 및 검색 될지를 정의
-
-
분석 예시
{ "content": "자율주행차는 미래 기술입니다." }→ nori_tokenizer가 분석하면 조사나 불필요한 어미가 제거되어 핵심 단어 중심으로 색인됨.
[자율주행차, 미래, 기술]
다음 포스팅에서는 실제로 데이터를 넣고 데이터를 검색해보는 실습방법에 대해서 간단하게 소개하겠다.
Comments