
[ElasticSearch] Part 1 - 설치 + 기본 사용방법 03
3) 한글 데이터 넣기
우리가 만든 korean_posts 인덱스에 실제 한글 문장을 몇 개 넣어보기위해 이번엔 POST 요청으로 문서(=글)를 추가한다.
-
예시 데이터 삽입 (Kibana Dev Tools에서 실행)
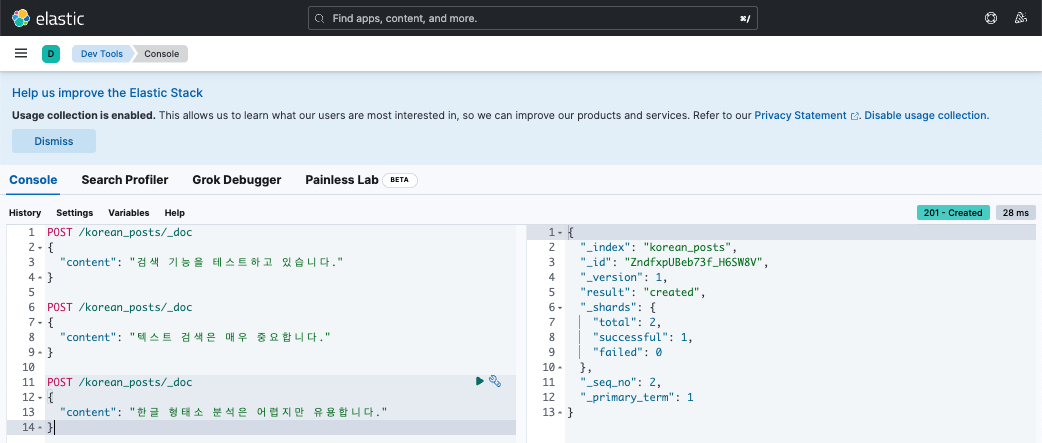
POST /korean_posts/_doc { "content": "검색 기능을 테스트하고 있습니다." } POST /korean_posts/_doc { "content": "텍스트 검색은 매우 중요합니다." } POST /korean_posts/_doc { "content": "한글 형태소 분석은 어렵지만 유용합니다." } POST /korean_posts/_doc { "content": "빠른 갈색 여우가 게으른 개를 뛰어넘다" } -
쿼리 실행 후 결과
4) 검색 테스트 (match 쿼리)
-
쿼리 실행(Kibana Dev Tools에서 실행)
GET /korean_posts/_search { "query": { "match": { "content": "검색" } } } -
쿼리 실행 후 결과
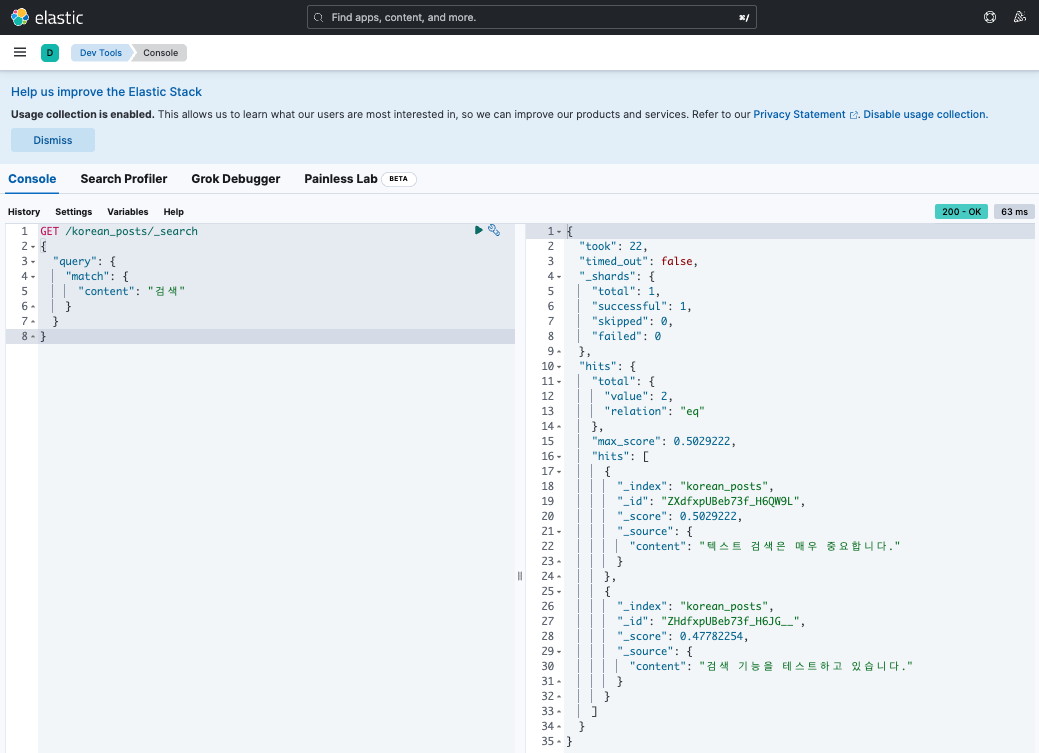
{ "took": 22, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 2, "relation": "eq" }, "max_score": 0.5029222, "hits": [ { "_index": "korean_posts", "_id": "ZXdfxpUBeb73f_H6QW9L", "_score": 0.5029222, "_source": { "content": "텍스트 검색은 매우 중요합니다." } }, { "_index": "korean_posts", "_id": "ZHdfxpUBeb73f_H6JG__", "_score": 0.47782254, "_source": { "content": "검색 기능을 테스트하고 있습니다." } } ] } } -
추가 테스트 : “빠르게”로 검색하면 형태소 분석하여 “빠른” 단어가 있는 해당 글을 검색
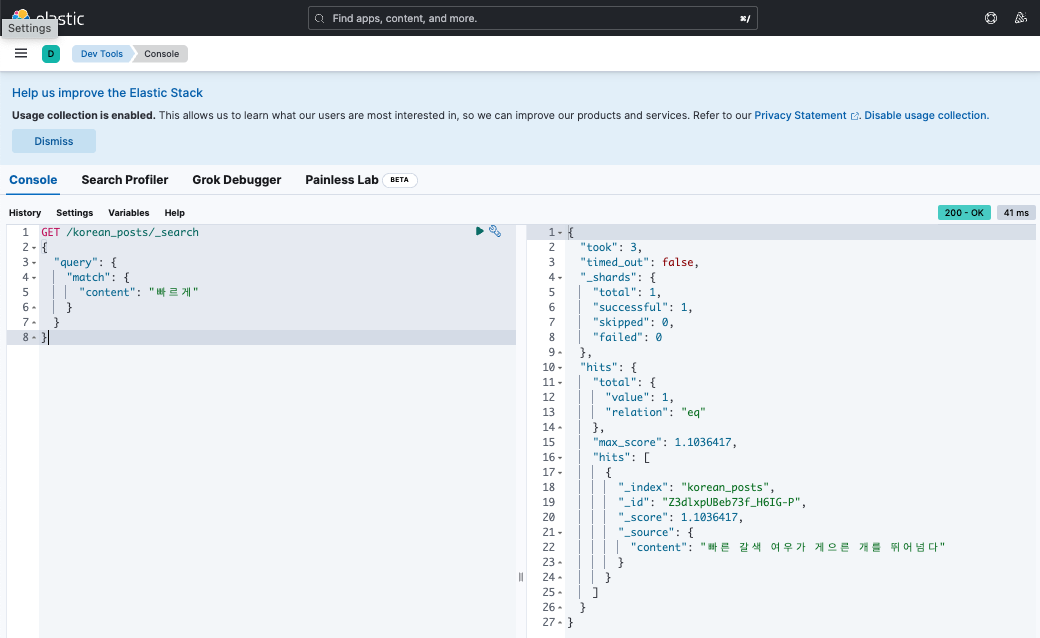
(3) 생성한 인덱스 조회 및 삭제
1) 인덱스 조회
-
인덱스 목록 조회 (간단한 방법)
GET /_cat/indices?v- /_cat/indices는 인덱스 정보를 표 형식으로 반환해주는 cat API 다.
- v는 헤더 포함(verbose) 옵션이다. → 컬럼 이름이 같이 나와서 보기 편하다.
-
결과 예시
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open articles_ko _abc123... 1 0 100 0 500kb 500kb green open autocomplete_test _xyz456... 1 0 50 0 150kb 150kb ... -
자주 쓰이는 cat API
-
cat API 리스트
• GET /_cat/indices → 인덱스 리스트 • GET /_cat/aliases → 별칭 • GET /_cat/count → 전체 문서 개수 • GET /_cat/nodes?v → 클러스터 노드 정보 • GET /_cat/health?v → 클러스터 상태 -
필요한 인덱스만 필터링 하고 싶을 때
GET /_cat/indices/articles_*?v이것은
articles_로 시작하는 인덱스만 보여준다.
-
2) 인덱스 삭제
-
전체 인덱스 삭제 (주의!)
DELETE /index_name예시)
DELETE /articles_ko- 주의 : 이건 인덱스 안의 모든 문서까지 삭제됨. 되돌릴 수 없다.
-
조건에 맞는 여러 인덱스 삭제
DELETE /articles_*- articles_로 시작하는 모든 인덱스 삭제
3) 인덱스 수정
- 기존 인덱스의 mapping, analyzer 같은 건 수정 불가
- 인덱스 구조(settings, mappings)는 생성이후에는 변경이 거의 불가능하다.
- 특히 tokenizer, analyzer 같은 설정은 변경 불가
대신 방법이 있다.
새 인덱스 만들고 데이터 마이그레이션 하는 것이다.
예시)
- articles_ko_v2라는 새 인덱스 생성
- 기존 인덱스에서 데이터 _reindex API로 복사
-
필요하면 기존 인덱스 삭제
POST /_reindex { "source": { "index": "articles_ko" }, "dest": { "index": "articles_ko_v2" } }
- POST /_reindex 란?
- 역할
- _reindex API는 한 인덱스의 데이터를 다른 인덱스로 복사할 수 있는 API다.
-
기본 사용 예시
POST /_reindex { "source": { "index": "articles_ko" }, "dest": { "index": "articles_ko_v2" } }source.index: 기존 인덱스 이름dest.index: 복사 대상 인덱스 이름 (미리 생성되어 있어야 함)
- 마이그레이션할 데이터 양이 많을 경우?
- 기본적으로 비동기가 아니라서 시간이 오래걸릴 수 있다.
- 수천 개는 빠르지만 수백만 건이면 느릴 수 있다.
- 성능 문제 방지를 위해 size, slices, conflicts, scroll 등 옵션 사용 가능
-
병렬로 나눠서 빠르게 처리
POST /_reindex { "source": { "index": "articles_ko" }, "dest": { "index": "articles_ko_v2" }, "conflicts": "proceed", "slices": 5 }slices: 5→ 5개의 병렬 작업으로 분산 복사conflicts: "proceed"→ 중복 ID 충돌 시 무시하고 진행
-
- 기본적으로 비동기가 아니라서 시간이 오래걸릴 수 있다.
-
응용 : query 조건 걸어서 일부만 복사 가능
예시) case_number ≥ 100 인 문서만 복사
POST /_reindex { "source": { "index": "articles_ko", "query": { "range": { "case_number": { "gte": 100 } } } }, "dest": { "index": "articles_ko_v2" } } - 마이그레이션 할 때 필드 구조가 다를 경우?
- 만약 복사 대상 필드가 없다면 오류가 안나고 그냥 null 로 처리된다.
-
필드명이 달라졌다면? 예시) member → user로 바뀌었다.
POST /_reindex { "source": { "index": "old_index" }, "dest": { "index": "new_index" }, "script": { "lang": "painless", "source": """ ctx._source.user = ctx._source.remove('member'); """ } }- ctx._source.member 값을 가져와서 ctx._source.user 에 넣고 member 필드는 제거
- 다른 필드 조작 예시
-
필드 이름만 변경
ctx._source.newField = ctx._source.remove('oldField'); -
값 자체를 바꾸기
ctx._source.status = "active";- 모든 문서의 status 값을 “active”로 설정한다는 뜻.
- 즉, 마이그레이션 대상 문서들마다 변경한다는 뜻이다.
- status 필드가 없던 문서에는 새롭게 추가되고, 있던 문서에는 무조건 덮어 써진다.
-
중첩 객체 수정
ctx._source.address.city = "Seoul";-
이 뜻은 다음과 같다.
{ "name": "홍길동", "address": { "city": "Jeonju",//-> "Seoul" "age": 30 } }
만약 중첩 객체가 없을 경우 오류가 난다.
-
그래서 체크를 해서 넣거나
"script": { "lang": "painless", "source": """ if (ctx._source.author != null) { ctx._source.address.city = "Seoul"; } """ } -
또는 새로 만들 수 있다. 그러면 모든 문서에 author라는 중첩필드를 생성 또는 덮어쓰기 한다.
"script": { "lang": "painless", "source": """ ctx._source.address = ["city": "Seoul", "age": 30]; """ }
-
-
- 역할
(4) 문서 수정 및 삭제
1) 문서 수정(부분 수정)
POST /index_name/_update/doc_id
예시)
POST /articles_ko/_update/abc123
{
"doc": {
"title": "수정된 제목입니다"
}
}
문서 ID가 abc123 인 문서의 title만 수정하는 방식이다.
2) 문서 삭제
DELETE /index_name/_doc/doc_id
예)
DELETE /articles_ko/_doc/abc123
[3] 마무리하며 – 실습 후 느낀 점
필자는 PostgreSQL FTS의 한계로 인해 한국어 검색에서 원하는 결과를 얻기 어려웠고,
이를 보완하기 위해 ES와 Nori 형태소 분석기를 실험해보았다.
직접 실습을 통해:
- Nori 분석기가 문장을 형태소 단위로 잘게 나누고
- “검색”, “분석” 같은 단어로도 다양한 문장이 매칭되는 것
을 확인할 수 있었다.
물론, ES를 처음 쓰는 입장에서는 약간의 러닝커브가 있지만,
한글 검색의 정확도와 유연성을 고려한다면 도입할 가치가 충분하다고 느꼈다.
다음 단계에서는 autocomplete, 동의어 사전 등을 활용한 더 정교한 검색 경험을 구현해볼 계획이다.
Comments