
[ElasticSearch] Part 2 - 고급 검색 기능 01
Elasticsearch(2)
[1] 개요
이번 장에서는 ES의 기본적인 검색 기능을 넘어서 실전 서비스에서 사용하는 고급 검색 기능, PostgreSQL과의 연동 방식까지 함께 살펴 볼 것이다.
(1) 주요 목표
- 정확한 검색 (match_phrase)
- 오타 교정 (fuzzy)
- 검색어 강조 (highlight)
- 검색어 우선순위 설정 (boost)
- 조건 필터링 (filter)
- 자동완성 (autocomplete)
- 인기 키워드 집계 (aggregation)
- 시간대별/조건별 Kibana 시각화
- PostgreSQL과의 데이터 연동
- 다국어(한국어 + 영어) 동시 검색
[2] 고급 검색 기능
(1) 자동 완성
자동완성은 보통 검색어 앞부분만 입력해도 추천리스트가 뜬다.
예시) “검” 입력 → “검색”, “검토”, “검사” 추천
이걸 구현하려면 ES에서 edge_ngram tokenizer를 사용한 custom analyzer를 설정해야한다.
1) 자동완성 전용 인덱스 만들기
-
인덱스 설정
PUT /autocomplete_test { "settings": { "analysis": { "tokenizer": { "autocomplete_tokenizer": { "type": "edge_ngram", "min_gram": 1, "max_gram": 20, "token_chars": ["letter", "digit", "whitespace"] } }, "analyzer": { "autocomplete_analyzer": { "type": "custom", "tokenizer": "autocomplete_tokenizer", "filter": ["lowercase"] } } } }, "mappings": { "properties": { "suggest": { "type": "text", "analyzer": "autocomplete_analyzer", "search_analyzer": "standard" } } } }- “검” → “검사”, “검증”, “검색” 같이 앞에서부터 유사한 단어들 매칭 가능
- “suggest” 필드에 자동완성용 텍스트를 저장해야 한다.
-
인덱스 분석
PUT /autocomplete_test { "settings": { "analysis": { "tokenizer": { //ES 문법에 따라 정해진 필드 이름 "autocomplete_tokenizer": { //사용자 정의 이름 (중복 불가) "type": "edge_ngram", //자동 완성 구현의 핵심 //예를 들어 "인공지능"이라는 텍스트가 들어오면 -> "인", "인공", "인공지", "인공지능" "min_gram": 1, //단어를 자를 최소 길이 "max_gram": 20, //단어를 자를 최대 길이 "token_chars": ["letter", "digit", "whitespace"] //어떤 종류의 문자들을 토큰화 할지 결정 } }, "analyzer": { //ES 문법에 따라 정해진 필드 이름 "autocomplete_analyzer": { //사용자 정의 이름 (중복 불가) "type": "custom", "tokenizer": "autocomplete_tokenizer", //위에서 만든 edge_ngram 토크나이저 기반 "filter": ["lowercase"] //모든 문자를 소문자화 } } } }, "mappings": { "properties": { "suggest": { "type": "text", "analyzer": "autocomplete_analyzer", //edge_ngram 으로 토큰 저장 //저장할 땐 “인공지능”을 “인”, “인공”, “인공지”, …로 저장 "search_analyzer": "standard" //standard 분석기로 검색 → 일반적으로 검색어 자체를 그대로 사용 //검색할 땐 사용자가 입력한 "인공" 같은 단어를 그대로 매칭해줌 } } } }-
tokenizer와 analyzer의 차이점
구분 설명 예시 tokenizer 문자열을 토큰(단어 조각) 으로 나누는 역할 “인공지능” → [“인공”, “지능”] analyzer tokenizer + 추가 필터들 (예: 소문자화, 불용어 제거 등)을 묶은 단위 “AI 2024” → [“ai”, “2024”] (lowercase 적용됨) 즉, analyzer는 tokenizer + filter들의 조합이다.
-
token_chars의 종류 (자주 쓰는 5가지)
| 값 | 의미 | | — | — | | “letter” | 문자 (AZ, 가하 등) | | “digit” | 숫자 (0~9) | | “whitespace” | 공백 | | “punctuation” | 문장 부호 (.,!?) | | “symbol” | 특수 문자 (@#$ 등) |
- 예시
- “token_chars”: [“letter”]
- “test123er” → [“test”, “er”]
- 최종 저장 토큰 : [“t”, “te”, “tes”, “test”, “e”, “er”]
- “token_chars”: [“letter”, “digit”]
- “test123er” → [“test123er”]
- 최종 저장 토큰 : [“t”, “te”, “tes”, …, “test123er”]
- “token_chars”: [“letter”]
-
예시 정리
token_chars 설정 “test 123 er” 처리 방식 결과 예시 [“letter”, “digit”] 공백 기준으로 나눔 [“t”, “te”, “tes”, “test”, “1”, “12”, “123”, “e”, “er”] [“letter”, “digit”, “whitespace”] 전체 문장 하나로 처리 [“t”, “te”, “tes”, “test”, “test “, “test 1”, “test 12”, “test 123”, “test 123 “, “test 123 e”, “test 123 er”]
- 예시
-
2) 자동완성용 데이터 삽입
autocomplete_test 인덱스에 아래처럼 추천 단어들을 넣어보자.
실제 검색어 추천 리스트라고 생각하면 된다.
-
Kibana Dev Tools에서 실행
POST /autocomplete_test/_doc { "suggest": "검색" } POST /autocomplete_test/_doc { "suggest": "검토" } POST /autocomplete_test/_doc { "suggest": "검사" } POST /autocomplete_test/_doc { "suggest": "검열" } POST /autocomplete_test/_doc { "suggest": "검은 고양이" }👉 필자는 한글로 일부러 비슷한 접두어로 시작하는 단어들을 넣었다.
3) 자동완성 검색 테스트
-
이제 “검”만 입력했을 때, 위의 추천어들이 잘 매칭되는지 테스트해보자
GET /autocomplete_test/_search { "query": { "match": { "suggest": "검" } } }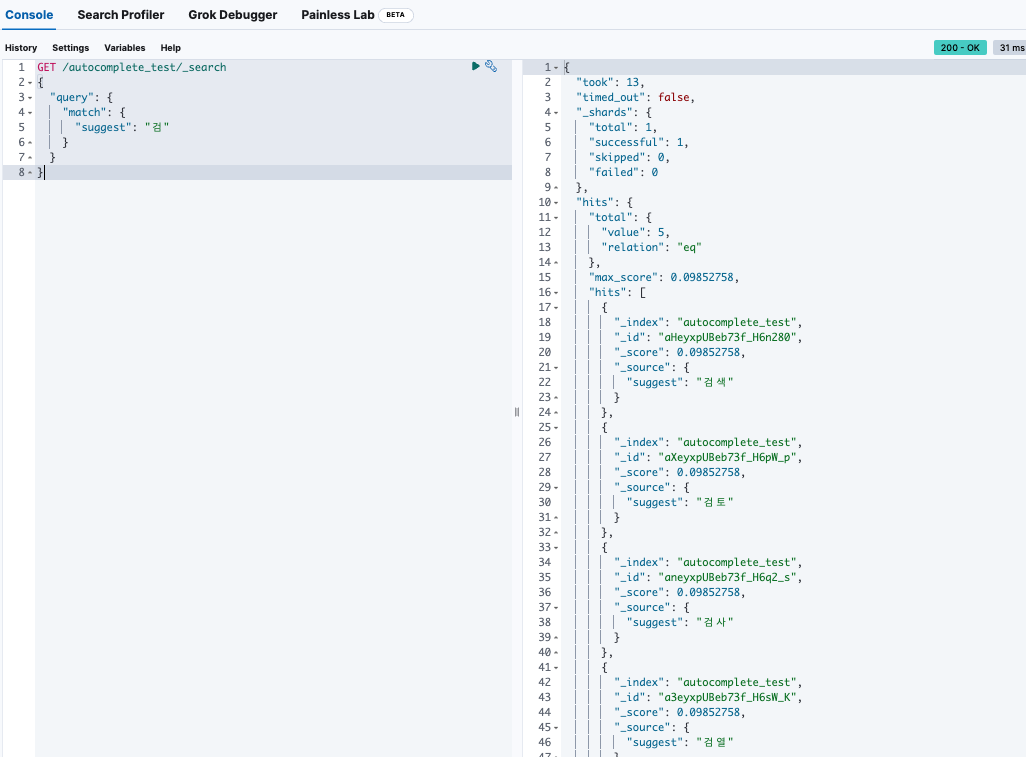
-
“겅” 이라고 입력했을 경우, 값이 나오질 않는다.
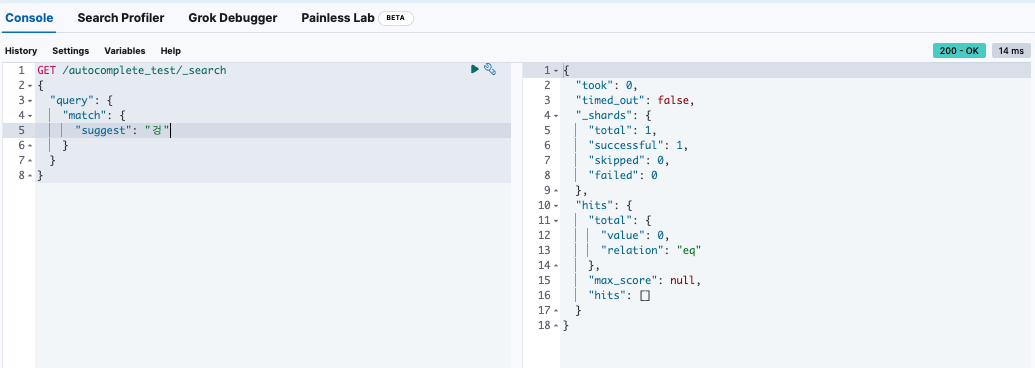
→ edge_ngram 토큰 리스트에 “겅”이 없기 때문
-
“색” 이라고 입력했을 경우, 값이 나오질 않는다.
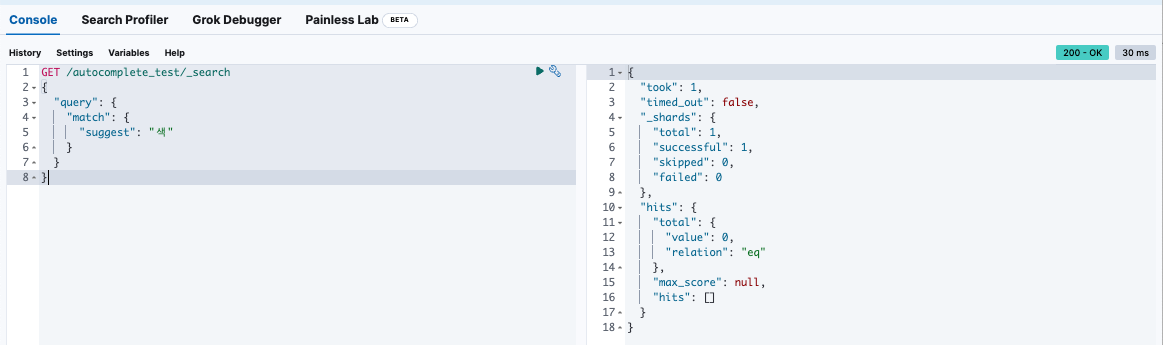
→ edge_ngram 토큰 리스트에 “색”이 없기 때문
-
edge_ngram은 앞글자 기준으로 추천을 한다.
4) 자동완성 추천어의 구성 방법
실습하면 알게되는 사실이 있다. 그 사실은 바로, 자동완성 추천어를 구성하려면 해당 추천어들을 추가해야한다는 것이다.
한국어에서 사용하는 단어는 대략 511,000개 이상이다. 그럼, 이 단어들을 전부 넣어야하는 걸까? 결론을 말하자면, 이 단어들을 전부 넣지 않아도 된다.
서비스에서 사람들이 검색할 가능성이 높은 데이터를 넣으면 충분하다.
-
실무에서 추천어를 구성하는 방법
방식 설명 🔹 서비스 데이터 기반 예: 쇼핑몰 → 상품명, 게시판 → 글 제목 🔹 검색 로그 기반 사람들이 실제로 검색한 키워드 중 자주 쓰인 것만 저장 🔹 자동 사전 생성 특정 DB 테이블에서 정기적으로 가져와서 ES에 넣기 🔹 외부 사전 활용 (선택) 한글 사전, 위키백과 제목 등 긁어와서 초기 데이터 구성
예를 들어 필자가 만든 웹앱에서 검색이 필요한 대상이
- 커뮤니티 → 게시글 제목, 키워드
이라면 이 “제목” 들을 미리 인덱싱해서 자동완성 대상으로 쓰면 된다.
예시로 이런 것도 가능하다.
PostgreSQL DB에 있는 title 컬럼을 기준으로 매일 1회 자동으로 ES에 추천어 업데이트
SELECT DISTINCT title FROM posts WHERE LENGTH(title) > 1 LIMIT 10000;
→ 이 결과를 스크립트로 ES에 넣고 자동완성 추천용으로 사용하면 된다.
아니면, 검색 로그를 분석해서 사용자들이 자주 쓰는 단어들로 유지하여도 충분하다.
다음 포스팅에서는 오타 교정 기능에 대해서 설명하겠다.
Comments