
[PostgreSQL] 전문 검색(FTS) 기능 Part 2
(3) 체험 세팅
직접 쿼리를 만들어서 기능을 체감하고자 한다.
-
조회를 해볼 table 생성
CREATE TABLE documents ( id SERIAL PRIMARY KEY, content TEXT, -- 원본 텍스트 content_tsvector TSVECTOR -- 전문 검색을 위한 변환 데이터 ); -
데이터 삽입
INSERT INTO documents (content) VALUES ('The quick brown fox jumps over the lazy dog'), ('A fast blue rabbit hops across the green field'), ('The small cat sleeps under a warm blanket'), ('A quick brown fox ran fast through the forest'), ('Big cats sleep under a warm blanket'), ('The lazy dog and the small cat are friends'), ('The fox is clever and jumps high'), ('A very quick response is needed'), ('A rabbit and a fox were playing together'); - 전문 검색을 위해 to_tsvector를 사용하여 content_tsvector 컬럼을 업데이트
- to_tsvector(‘english’, content) → content 컬럼을 전문 검색이 가능한 형태(tsvector)로 변환해서 저장
- 꼭 하지 않아도 되지만 검색 성능을 최적화 하기 위해서는 반드시 하는 것이 좋다.
UPDATE documents SET content_tsvector = to_tsvector('english', content); - GIN 인덱스 생성 (검색 성능 최적화, 검색 속도를 빠르게 하기 위해 GIN 인덱스 생성)
- 데이터가 많아지면 느려지기 때문에 미리 content_tsvector 컬럼을 만들어서 GIN 인덱스를 적용하는 것이 좋다!
CREATE INDEX content_tsvector_idx ON documents USING GIN(content_tsvector);- 반드시 3번과 4번을 해야하는 것은 아니지만 성능 최적화를 위해 content_tsvector 컬럼을 업데이트하고 GIN 인덱스를 적용하는 것이 강력히 추천됨!
(4) 주요 기능 예제 쿼리
-
to_tsvector (텍스트를 색인 가능한 형태로 변환)
SELECT to_tsvector('english', 'The quick brown fox jumps over the lazy dog');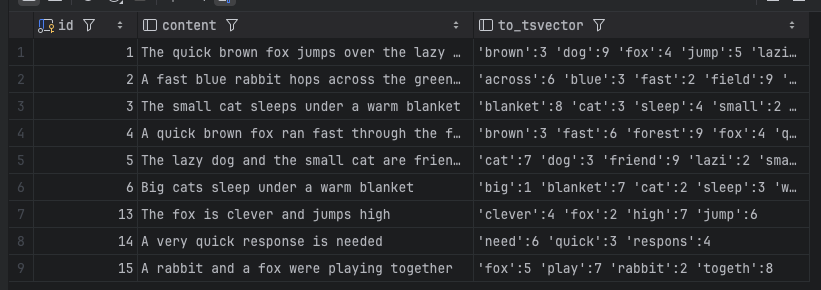
SELECT id, content, to_tsvector('english', content) FROM documents;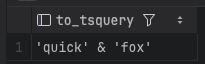
-
to_tsquery (검색어 변환 및 논리 연산자 지원)
quick과 fox가 둘 다 포함된 문서 검색 (순서 상관 없음)
SELECT to_tsquery('english', 'quick & fox');
SELECT id, content FROM documents WHERE content_tsvector @@ to_tsquery('english', 'cat');
SELECT id, content FROM documents WHERE content_tsvector @@ to_tsquery('english', 'quick & fox');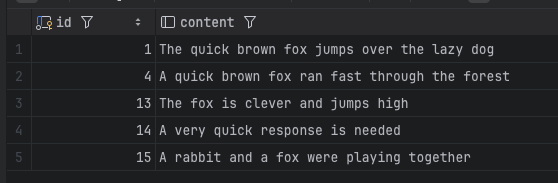
SELECT id, content FROM documents WHERE content_tsvector @@ to_tsquery('english', 'quick | fox');
SELECT id, content FROM documents WHERE content_tsvector @@ to_tsquery('english', 'jump');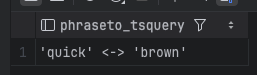
-
phraseto_tsquery (구문 검색, 단어 순서 유지)
- <-> 연산자 사용: 연속된 단어로 존재해야 검색됨.
- “quick”과 “brown”이 순서대로 포함된 문서만 검색 가능.
SELECT phraseto_tsquery('english', 'quick brown');
SELECT id, content FROM documents WHERE content_tsvector @@ phraseto_tsquery('english', 'quick brown');
SELECT id, content FROM documents WHERE content_tsvector @@ phraseto_tsquery('english', 'fox jump');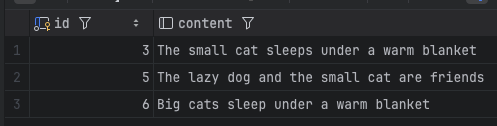
-
실시간 변환 검색 (to_tsvector 사용)
만약 미리 to_tsvector 컬럼을 만들지 않았다면, 아래처럼 to_tsvector를 직접 적용할 수도 있다.
- 단점 : 인덱스를 활용하지 못해서 속도가 느릴 수 있음.
미리 to_tsvector 컬럼을 만들어서 GIN 인덱스를 적용하는 것이 더 효율적!
SELECT id, content FROM documents WHERE to_tsvector('english', content) @@ to_tsquery('english', 'cat');
- 단점 : 인덱스를 활용하지 못해서 속도가 느릴 수 있음.
-
불용어(Stopwords) 제거 테스트
“the”, “over” 같은 불용어가 자동으로 제거됨.
SELECT to_tsvector('english', 'The quick brown fox jumps over the lazy dog'); -
단어 어간(stemming) 처리 테스트
“running”, “runs” → “run”으로 변환됨.
SELECT to_tsvector('english', 'running runner runs');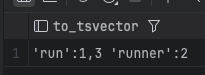
(5) 요약
| 기능 | 설명 | 순서 고려 |
|---|---|---|
| to_tsvector(text) | 텍스트를 검색 가능한 형태로 변환 | X |
| to_tsquery(text) | 논리 연산자를 사용한 검색 (&, , !) |
X |
| phraseto_tsquery(text) | 문구 검색을 위한 쿼리 생성 (<->) | O |
| @@ 연산자 | tsvector 컬럼과 tsquery를 매칭하여 검색 | X |
| GIN 인덱스 | 검색 속도를 빠르게 하기 위해 사용 | X |
- 검색 최적화를 위해 컬럼을 미리 to_tsvector로 변환하여 GIN 인덱스를 생성.
- 단어 포함 여부 확인: to_tsquery
- 문장 그대로 검색(구문 검색): phraseto_tsquery
참고사항 : english는 텍스트를 처리할 언어 설정을 지정하는 역할이다. 기본값이 english로 생략 가능하다.
SELECT to_tsvector('The quick brown fox jumps over the lazy dog');
SELECT to_tsquery('quick & fox');
SELECT phraseto_tsquery('quick brown');
한국어 검색 (한국어 형태소 분석 적용)
SELECT to_tsvector('simple', '빠른 갈색 여우가 게으른 개를 뛰어넘다');
--Postgresql에는 korean 언어 설정이 기본적으로 포함되어 있지 않음
--english, french, german 등은 기본적으로 지원
--PGroonga와 같은 한국어 형태소 분석기 확장 설치를 하기 전엔 simple로 대체 가능

한국어 검색에서 불용어 제거 및 어간 분석이 제한적이다. 아래 쿼리 실행 결과는 “빠르게”, “달렸다”가 그대로 저장된다. (어간 분석이 없음) 그래서 PGroonga 설치 후 실행하면 “빠르다”, “달리다”로 변환 가능하다.
SELECT to_tsvector('korean', '나는 빠르게 달렸다');
기본 설정 확인 방법
SHOW default_text_search_config;
기본 값을 english에서 다른 언어로 변경하는 방법
ALTER DATABASE mydb SET default_text_search_config = 'korean';
다음 포스팅에서는 한국어로도 FTS가 가능 여부와 PostgreSQL의 추가기능에 대해 소개하겠다.
Comments