
[Django] 100만 건 이상의 데이터를 효율적으로 엑셀/CSV로 다운로드하는 방법
최근 100만 건이 넘는 데이터를 웹에서 다운로드할 수 있도록 처리해야 했다.
사용자 입장에선 그냥 버튼 하나 클릭해서 “엑셀 다운받기”지만, 백엔드에서는 꽤 신경 써야 할 부분이 많았다.
🔍 문제 상황
- 총 데이터 수: 1,025,731건
- 사용자 요구: Excel 또는 CSV로 전체 데이터를 다운로드 가능해야 함
- 초기 방식:
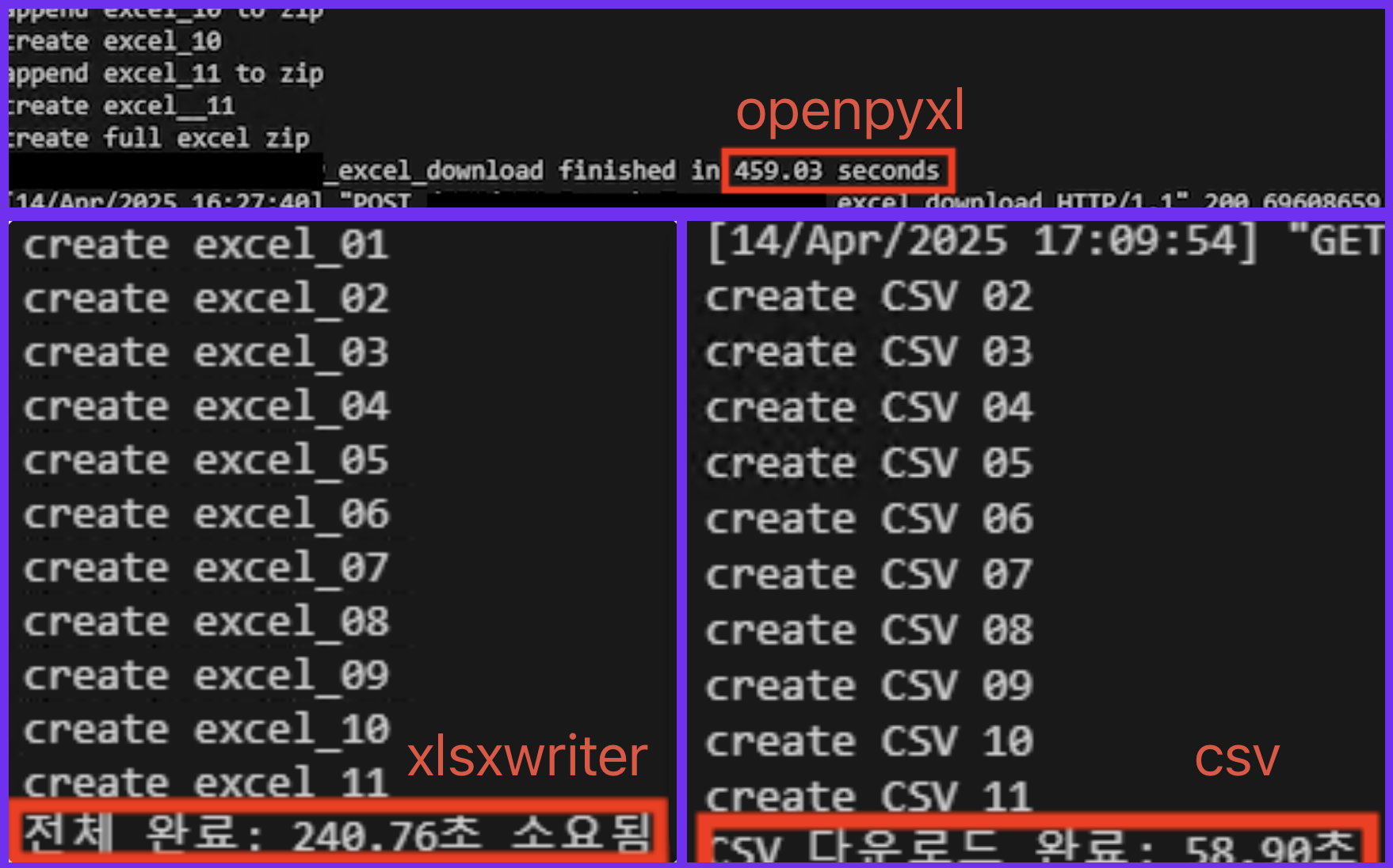
openpyxl사용 - 문제: 엑셀 생성에만 약 7분이나 걸렸다.
🧪 시도한 방법들
| 방식 | 설명 | 소요 시간 | 파일 형식 | 비고 |
|---|---|---|---|---|
openpyxl |
기본 엑셀 생성 방식 | 약 7분 | .xlsx |
가장 느림 |
xlsxwriter |
성능 개선용 엑셀 생성기 | 약 2분 | .xlsx |
스타일은 없음 |
csv + zipfile |
텍스트 기반 처리 | 1분 내외 | .csv |
가장 빠름 |
📸 실제 실행 로그도 같이 남겨두었다.
🛠 구현 방식 요약
- 청크 단위로 파일 분할 (
CHUNK_SIZE = 100_000) - 일정 건수마다 새로운 파일을 만들고 ZIP으로 압축
- Django의
HttpResponse로 zip 파일 반환 - 파일명은 자동으로
export_01.xlsx,export_02.xlsx식으로 생성
📈 결과 정리
openpyxl: 약 7분 → 단순히 스타일링까지 포함된 Excel이 필요할 경우 고려xlsxwriter: 약 2분 → 빠르면서도.xlsx포맷 유지 가능csv: 1분 이내 → 정말 빠르다. 단순 분석용이라면 최고의 선택
🤔 왜 이렇게 차이날까?
세 가지 방식은 내부 처리 방식 자체가 다르다 보니 성능 차이가 크게 난다.
1. openpyxl
- 순수 Python으로 구현된 엑셀 처리 라이브러리
.xlsx파일 구조를 직접 다루기 때문에 상대적으로 느림- 셀 스타일, 병합, 서식 등을 지원하면서도 유연하지만, 그만큼 무거움
2. xlsxwriter
- 내부적으로 C 구현과 버퍼 기반 처리로 성능이 빠름
- 엑셀 스타일 기능은 일부 제한되지만 속도 면에서는 openpyxl 대비 2~3배 빠름
- 메모리 상에 시트를 구성한 뒤 한 번에 저장하는 구조
3. csv
- 그냥 텍스트 줄을 쉼표로 이어붙이는 단순한 형식
- 스타일이나 시트 구조가 없어서 가장 빠름
- 대신 필드 구분, 인코딩, 특수문자 처리에 신경 써야 할 경우도 있음
결론적으로는,
- 스타일이 필요한 보고서라면
xlsxwriter - 속도가 최우선이라면
csv - 특별한 포맷이 필요할 경우에만
openpyxl
💡 느낀 점
- 엑셀 다운로드도 데이터가 많아지면 무조건 “성능 이슈”로 이어진다
- 대부분의 경우
.xlsx가 아니어도 괜찮다면 CSV로 가는 게 UX에 훨씬 낫다 - 실제 데이터를 어떻게 잘라서 나눌 것인지, 어떻게 압축해서 보낼 것인지도 중요한 설계 포인트
- 기능 자체보다 사용자가 기다리지 않도록 만드는 게 핵심
💻 핵심 코드 요약
아래는 각 방식별로 데이터를 청크 단위로 나눠서 압축 파일로 내보내는 핵심 흐름이다.
1. 🐢 openpyxl 방식 (약 7분)
import openpyxl, zipfile, io
CHUNK_SIZE = 100_000
zip_buffer = io.BytesIO()
zip_file = zipfile.ZipFile(zip_buffer, 'w')
wb = openpyxl.Workbook()
ws = wb.active
ws.append(columns)
for row in queryset:
ws.append(row)
row_count += 1
if row_count >= CHUNK_SIZE:
buffer = io.BytesIO()
wb.save(buffer)
zip_file.writestr(f"excel_{file_index:02d}.xlsx", buffer.getvalue())
# 새 워크북 초기화
2. ⚡ xlsxwriter 방식 (약 2분)
import xlsxwriter, io
current_buffer = io.BytesIO()
workbook = xlsxwriter.Workbook(current_buffer, {'in_memory': True})
worksheet = workbook.add_worksheet()
for row in queryset:
worksheet.write_row(current_row, 0, row)
row_count += 1
current_row += 1
if row_count >= CHUNK_SIZE:
workbook.close()
zip_file.writestr(f"excel_{file_index:02d}.xlsx", current_buffer.getvalue())
# 새 워크북 초기화
3. 🚀 csv + zipfile 방식 (약 1분 내외)
import csv, zipfile, io
current_buffer = io.StringIO()
writer = csv.writer(current_buffer)
writer.writerow(columns)
for row in queryset:
writer.writerow(row)
row_count += 1
if row_count >= CHUNK_SIZE:
zip_file.writestr(f"data_{file_index:02d}.csv", current_buffer.getvalue())
# 새 버퍼 초기화
4. 전체 소스 코드
📂 전체 소스 코드는 GitHub에서 확인 가능
- 🔗 GitHub: github excel-export-optimization 주소
💡 보너스
queryset은.iterator()로 받는 걸 추천 (chunk_size와 함께 사용)-
이유는 “메모리 효율”과 “성능”에 직접적으로 큰 영향을 준다.
-
내부적으로 cursor를 사용해서 일정한 크기만큼만 메모리에 올림
-
루프 돌면서 한 번에 1000개씩만 가져오고, 처리되면 버림
→ 메모리 사용량 매우 낮음 + 대용량 처리에 적합
-
-
.iterator()는 데이터 변경 없이 읽기만 할 때 사용하는 게 원칙
-
- 파일 이름은
file_index로 자동 증가 (:02d→ 두 자리 숫자)
✍️ 마무리
엑셀 다운로드 기능을 그냥 단순히 “데이터 덤프”로 생각했었는데,
이번 작업을 하면서 꽤 많은 기술적 고민과 선택이 필요하다는 걸 느꼈다.
앞으로도 실무에서 겪은 문제, 직접 구현한 해결 방법들을 계속 정리해서 올릴 계획이다.
Comments